To navigate dynamic environments, autonomous vehicles (AVs) should be able to process all information available to them and use it to generate effective driving strategies. Researchers at the University of California, Berkeley, have recently proposed a social perception scheme for planning the behavior of autonomous cars, which could help to develop AVs that are better equipped to deal with uncertainty in their surrounding environment.
“My research has focused on how to design human-like driving behaviors for autonomous cars,” Liting Sun, one of the researchers who carried out the study, told TechXplore. “Our goal is to build AVs that do not only understand human behavior, but also perform in a similar way in multiple aspects, including perception, reasoning and action.”
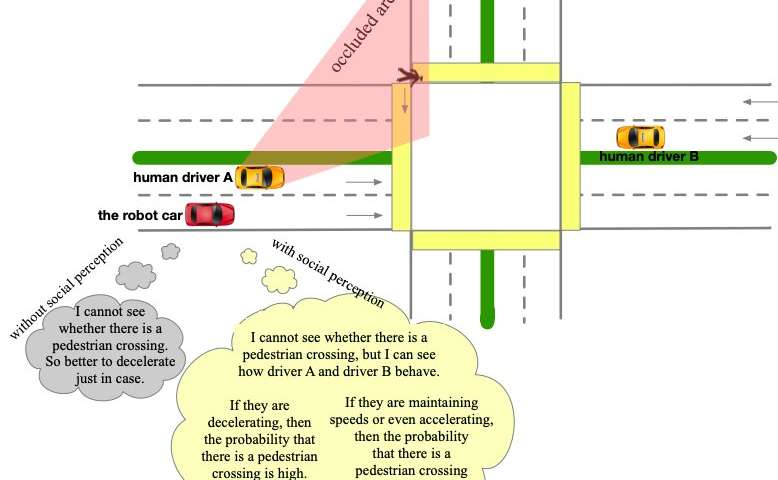
Sun and her colleagues observed that human drivers tend to treat other vehicles as dynamic obstacles, often inferring additional information from their behavior on the road. This information is generally occluded environment information or physically undetectable social information.
“It would be very important and beneficial for AVs to behave in the same way, as this would make them more intelligent, more human-like and ultimately safer,” Sun said. “In this work, we let AVs treat all other road participants as dynamic and distributed sensors.”
The social perception scheme proposed by Sun and her colleagues essentially treats all vehicles and obstacles on the road as sensors distributed in a sensor network. This allows AVs to observe both individual behaviors and group behaviors, using their observations to uniformly update different types of uncertainties within a “belief space.” The scheme particularly focuses on physical state uncertainties (e.g. caused by occlusions or limited sensor range) and social behavioral uncertainties (e.g. local driving preferences).
The scheme then integrates updated social perception beliefs with a probabilistic planning framework based on model predictive control (MPC), the cost function of which is learned via inverse reinforcement learning (IRL). This combination between a probabilistic planning module and socially enhanced perception allows the vehicles to generate defensive behaviors that are socially compatible and thus not overly strict.
“By observing the behaviors of others and comparing them to prior behavior models, AVs can reason about possible states of the undetectable variables using only its own sensors,” Sun said. “This can help the AVs reduce perception uncertainties, just like human do. Compared to other existing approaches, the idea in this work effectively extends the perception ability of the AVs without any additional hardware, and can help to generate safer and more efficient maneuvers.”
Sun and her colleagues evaluated their framework in a series of simulations featuring representative scenarios with sensor occlusions. They found that by imitating humans’ social perception mechanisms, the perception module detected fewer uncertainties, ultimately generating safer and more efficient AV behaviors via a non-conservative defense planner.
“Practically, this nice feature can make AVs more efficient in the presence of occlusions, as well as more adaptable in new driving environments, because they can quickly infer and learn about the physically undetectable social information in their surroundings,” Sun explained.
In the future, the social perception scheme devised by this team of researchers could inform the development of self-driving cars that can navigate continuously changing environments more effectively. Sun and her colleagues are now planning to develop their framework further, changing some of its assumptions and making it easier to apply in real-life situations.
“To infer additional uncertain information from the behaviors of other road participants, AVs should be equipped with prior behavior models that can approximate the actual behaviors of others,” Sun explained. “In the current work, we assume that all other road participants are rational optimizers and approximate their behavior generation models via reward functions. In our future work, we are going to relax the assumption of rationality to make the approximation more practical.”
